Context Compounds: How Falcon Reaches 92% Accuracy by Getting Out of the Model’s Way
Anyone who has seriously tried to build an AI agent for production operations has run into the same wall: accuracy.
Not demo accuracy. Not benchmark accuracy. The accuracy that matters when a P1 fires at 3 AM and an agent has to investigate across noisy telemetry, incomplete data, tangled dependencies, and conflicting signals, and has to be right often enough that an on-call engineer trusts its output at face value. That number is the one that separates a novelty from a product.
This post explains how NeuBird's new Falcon engine closed the gap, why the lift keeps compounding months after launch, and what it tells us about where accuracy in AI SRE actually comes from.
The Accuracy Ceiling in AI for Production Operations
Hawkeye, our previous generation engine, averaged around 80%. That was good enough to ship and good enough to win customers, but not good enough for trust at face value. We hit the ceiling about six months ago. Frontier models hadn't stopped improving, they were improving fast, but the way we were asking them to investigate hadn't kept up with how their agentic capabilities had evolved.
Two years ago, frontier models were narrow reasoners that needed tight scaffolding, hand-crafted prompts, and constrained tool surfaces. By the end of 2025, they had become genuinely agentic: capable of long-horizon investigation, dynamic tool selection, and hypothesis revision across multiple steps. Our harness was still treating them like the 2023 version.
So we rewrote it. Not the context platform (we didn't touch the core data virtualization layer that's been our foundation since day one). We rewrote the harness: the orchestration and reasoning loop sitting between the frontier model and the Agent Context Platform. That rewrite became Falcon, which replaced Hawkeye earlier this year, and which is approaching 92% accuracy on the same investigations that capped Hawkeye at 80%.
The shift in Falcon is subtle but architecturally load-bearing. In Hawkeye, we injected context into the model. The harness decided in advance what telemetry, topology, and prior investigations were relevant, packaged them up, and fed them into a constrained reasoning loop. That worked for the model generation it was built for. But once frontier models became genuinely agentic, injection became the ceiling. A reasoner that can investigate on its own doesn't need to be handed a pre-assembled context bundle. It needs the ability to find what it needs, to pose sub-questions, discover relevant context, pull the right slice of telemetry, and revise as evidence accumulates.
So Falcon stopped pushing context into the model. Instead, it pushes the model into the context layer and makes context discoverable. The harness exposes the Agent Context Platform as a queryable surface and lets the model reason about what it needs, when it needs it. The platform's job is to make sure that when the model reaches for something, the right structured, enriched, trustworthy answer is there.
The 15-point lift was a step-change on its own. But the more interesting result has shown up in the months since: accuracy has continued to climb. Two curves are moving at once. Frontier models keep getting better, and because Falcon discovers context on its own terms rather than being handed a fixed bundle, every model improvement translates directly into better investigations. At the same time, the context swarm keeps enriching the substrate: more dependencies mined, more schemas annotated, more alert patterns baselined. The two improvements aren't independent. They reinforce each other. Early testing with the newest generation of frontier models is pointing the same direction: another measurable lift, with zero changes to the harness and zero changes to the platform.
That experience clarified something we already believed but hadn't said out loud: the bottleneck in production operations isn't model reasoning capability. It's whether the model can get to the right context when it needs it. The industry already has a name for the same insight from the operator's side: Mean Time to Understand. Survey work from RSA 2025 found that 79% of incident response teams spend at least 20% to 40% of their time in the analysis phase, and over half of those say it's more than 40%. Detection is mostly solved. Resolution is mostly mechanical. Understanding is where the hours go, and understanding is built in the context layer.
Where Accuracy in AI SRE Actually Comes From
Falcon answered a strategic question for us. There are two plausible places accuracy can come from in production ops.
The first is reasoning capability: the model is the constraint, and pushing the ceiling means making the reasoner smarter.
The second is input quality and access: the reasoner isn't the constraint. The signal-to-noise ratio of what it can reason over, and how easily it can get to the right piece of it, is the real gating factor.
Falcon told us the second answer is the right one. When we unblocked the model and gave it the ability to discover context on its own terms, the accuracy gains came from the platform, not from the model getting fundamentally smarter. The raw reasoning capability was already there. What we needed to do was stop getting in its way and keep enriching the substrate.
From that point forward, our strategy became obvious: frontier reasoning is a fast-moving target, and context is a durable one.
Frontier labs ship models every few months that are materially better at exactly the capabilities that matter for production investigations: tool use, long-horizon reasoning, hypothesis revision, agentic loops. That curve is steep and it isn't slowing. A platform that's positioned to absorb each of those releases automatically, without rebuilding the harness or changing the architecture, gets a free lift on every cycle. We've already seen this play out across the last three frontier model generations, and early signals from the next one point the same direction.
Context, by contrast, compounds. Every investigation enriches the substrate. Every dependency mined, every schema annotated, every alert pattern baselined, every skill written by a customer becomes durable structure that every future investigation benefits from. Context built today is still useful in two years; the specifics of any given reasoning approach today will be obsolete by then.
The two trends combine multiplicatively. A better reasoner running over richer substrates is a much bigger gain than either alone. And because we don't own the reasoner curve and don't need to, our entire engineering investment goes into the substrate.
The Three Principles Behind Context Engineering
Context engineering is a discipline, not a feature. Over the course of building Hawkeye and then Falcon, we've landed on three principles that guide every decision we make about the platform.
Raw Telemetry Is Not Context
Every production environment is already drowning in data: metrics, events, logs, traces, alerts, config, change history, deployment records. More of it every year. Raw telemetry describes what happened; context describes what it means in relation to everything else.
A CPU spike on its own is a data point. A CPU spike correlated with a rollout that changed memory limits on an upstream service, which shares a node with two other workloads, and which has a history of cascading into the payment path, that's context.
The gap between the two is not closed by collecting more data. It's closed by building structured representations, schema annotations, and relational models that aren't present in the raw stream. And it has to be assembled live: production environments change faster than any pre-built index cycle can keep up with. The service that rolled out twenty minutes ago, the dependency that shifted since the last baseline refresh, the config change that hasn't been captured yet, these are exactly the events that matter for the next investigation. Every investigation is a fresh query against ground truth, not a lookup into yesterday's snapshot.
Context Is Built by Machines, Owned by Humans
Modern production environments operate at a scale no team can hand-curate. Tens of thousands of services, millions of metrics, billions of log lines, topology that changes by the hour. The only way to keep context current at that scale is to have specialized agents doing the enrichment continuously: sampling live telemetry, mining investigations, rebuilding dependency graphs, updating behavioral baselines. That's the machine side.
But context without human domain expertise is an empty scaffold. The tribal knowledge that lives in a team's heads, how this company's systems fail, what the "normal weirdness" looks like, which runbook actually works when the official one doesn't, has to be contributed. Our architecture splits the labor cleanly: machines build the substrate at scale, humans contribute the expertise that only they have.
Context Enriches Itself from Every Investigation
Every investigation an agent completes is a data point that teaches the platform something: a dependency confirmed, a hypothesis ruled out, a sequence of queries that actually led to the answer. A platform that discards that signal starts over every time. A platform that captures it, distills it into durable, reusable structures, gets smarter with every incident it touches. This is the compounding property of the context layer, and it's why frontier model improvements and context agent improvements reinforce each other rather than saturating.
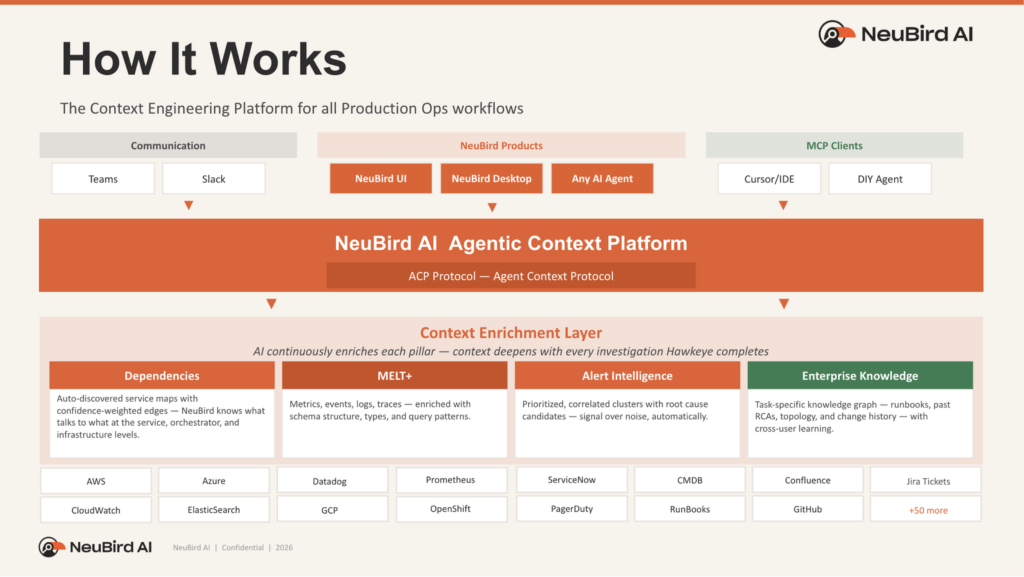
Inside the Context Swarm: What Makes an Agent Context Platform Work
For the model to discover context on its own, the context has to be worth discovering. Raw telemetry isn't. A service map generated from documentation six months ago isn't. A log search that returns ten thousand lines with no structure isn't. The context that makes Falcon work is built continuously by a swarm of specialized agents whose only job is to turn raw production data into something a frontier model can reason over productively.
At the foundation sits data virtualization. The Agent Context Platform exposes every telemetry source (metrics, logs, traces, alerts, events, config) as a queryable, relatable surface. Not a copy. Not a pre-indexed snapshot. A live, typed, schema-aware view that can be joined across sources, filtered programmatically, and correlated at query time. This is what turns "go look at Datadog, then CloudWatch, then Prometheus, then try to line them up" into a single coherent substrate the model can reason against.

On top of that foundation, four enrichment pillars are continuously maintained by specialized context agents:
- Schema annotations on MELT+ turn raw, source-specific telemetry (metrics, events, logs, traces, plus alerts, events, and config) into a typed interface a frontier model can query with confidence. When the model asks for p92 latency on the checkout service in the last fifteen minutes, the platform knows what that question means in this specific environment, against this specific data, without the model having to guess.
- Dependency graphs at three levels (infrastructure, orchestration, and application) let an agent reason about blast radius the way a seasoned engineer does. "This pod's OOM kill is cascading because this upstream service depends on it, which is running on this node, which is also hosting these three other workloads, two of which are on the critical path for revenue." That kind of reasoning isn't something a frontier model does from raw logs. It's something it does instantly if the dependency structure is already there to query.
- Statistical models for alert intelligence address the noisiest part of telemetry. Roughly 70% of alerts in most environments aren't actionable, and the actionable ones often fire alongside floods of unrelated noise. Context agents build behavioral baselines for every alert source, learn correlation patterns across alert clusters, and identify which alerts are symptoms versus causes. When a frontier model investigates an incident, it isn't looking at a raw alert stream; it's looking at a prioritized, correlated, causally-ordered view of what's actually happening. This is what lets NeuBird AI customers see roughly 78% reduction in alert noise, reclaiming time previously lost to alert fatigue and manual triage.
- Knowledge distillation and memory harvesting turn every completed investigation into durable, reusable structure: patterns of failure, query strategies that worked, dead ends that didn't. This memory is available to every future investigation, on every similar incident. A team that coaches the platform once on how they handle a specific failure mode sees that coaching applied permanently.
Underneath, agent personas (SRE, Infrastructure, APM, Storage, Security, plus custom personas for domain-specific workflows) select the slice of context and the reasoning pattern appropriate for their job. The platform doesn't get rebuilt for each persona. The context swarm keeps enriching the underlying substrate; every persona benefits simultaneously.
The Skills Loop: Where Humans Come In
There's a version of this story that ends at machines: the swarm does the heavy lifting, the frontier model reasons, the agent resolves the incident, the humans go do something else. That version is wrong, and more importantly, it's bad architecture.
No matter how good the platform gets at inferring structure from telemetry, there's a layer of knowledge it can't derive from data alone. How this team handled the weird failure mode that only shows up during month-end close. The undocumented convention that the payments service always gets restarted before the inventory service, never after. The three lines in a runbook the official documentation got wrong but the on-call rotation has known for two years. That knowledge lives in people's heads, and the way it becomes operational is that people contribute it. Not by filling out a form, not by waiting for a vendor to model it, but by writing it down in a format the agent can actually use.
The format we've converged on is skills: structured knowledge files, written in markdown with YAML frontmatter, that encode how to approach a specific problem. A skill for hunting brewing incidents across your monitoring stack. A skill for running a pre-oncall sweep. A skill for investigating a specific class of Kubernetes failure the way your senior SRE does it. Each one packages the reasoning pattern, the query strategy, and the resolution playbook for a scoped domain. Write one in fifteen minutes of markdown; the agent picks it up and uses it immediately, with no code changes, no deployment pipeline, no SDK.
Skills are the counterpart to the context swarm. The swarm builds the substrate at machine scale. Skills contribute the expertise that only humans have. Neither side is complete without the other. A platform with rich context but no skills is a generalist. A platform with rich skills but thin context is a specialist working blind.
This is also why the skills interface matters so much. If contributing knowledge is hard (engineering resources, vendor tickets, six-week integration projects), it doesn't happen, and your team's expertise stays locked in their heads. If it's easy (fifteen minutes, markdown, version-controlled, reviewable), it compounds. Every skill your team writes is leveraged on every future investigation. Every skill the open ecosystem writes is leverage you didn't have to build.
Our skills hub is FalconClaw, fully compatible with the OpenClaw ecosystem, with bi-directional integration so that NeuBird's production ops capability is itself accessible as a ClawHub skill inside other agents. We've written about it in depth elsewhere. What matters here is the principle: your team's expertise is not a problem to be solved by machine learning. It's an asset to be made operational.
Why This Matters for Reducing MTTR and MTTU
For engineering leaders evaluating AI for incident management and production ops, the architecture described above translates to three concrete outcomes.
Investigations compress from hours to minutes. When the model can discover context on its own and the substrate is already enriched, root cause analysis doesn't require an on-call engineer to open six dashboards in sequence. Falcon traces causation (not just correlation) across telemetry, change history, and dependencies, and produces a complete reasoning chain. That's the difference between a 120-minute investigation and an 11-minute one.
Alert noise drops without losing real signal. Statistical baselines plus correlation across clusters means the agent isn't competing with the engineer for attention during an incident. The prioritized, causally-ordered view cuts through the 70% of alerts that aren't actionable.
Your team's expertise becomes an asset, not a dependency. A skill written once is applied on every future investigation. Tribal knowledge survives team changes, vacations, and the 3 AM incident where the one person who's seen this before is out.
The Bet
Hawkeye got us to 80%. Falcon is approaching 92%, and the path there ran through the context layer, not through a smarter reasoner. The next frontier model release will move us further still, automatically. The next batch of customer-contributed skills will move us further still. Both curves keep climbing, and both feed each other.
That's the bet. The best agents aren't the ones with the biggest models. They're the ones their users can teach, running on a platform that gets smarter every time they do.
Key Takeaways
- The accuracy bottleneck in AI for production operations is not model reasoning capability. It is whether the model can get to the right context when it needs it.
- Falcon, NeuBird AI's new reasoning engine, reached roughly 92% accuracy by stopping the practice of injecting pre-assembled context and instead letting the model discover context from a queryable Agent Context Platform.
- Context engineering compounds: every enriched dependency, schema annotation, alert baseline, and customer-written skill becomes a durable structure that every future investigation benefits from.
- Raw telemetry is not context. Context is built live from MELT+ schema annotations, three-level dependency graphs, statistical alert intelligence, and memory harvested from every prior investigation.
- The best production ops agents are the ones users can teach. Skills (markdown knowledge files written in minutes) encode human expertise the platform cannot derive from telemetry alone.
Frequently Asked Questions
Related Reading
- What is AI SRE? — How AI agents investigate, diagnose, and resolve production incidents autonomously.
- What is Root Cause Analysis (RCA)? — The diagnostic process at the heart of Falcon's value.
- What is Alert Fatigue? — The noise problem that statistical alert intelligence addresses.
- Introducing the NeuBird AI Production Ops Agent — The launch announcement with full platform details.
- 2026 State of Production Reliability and AI Adoption Report — Industry data on how engineering teams are navigating production complexity.
Written by

Francois Martel
Field CTO
Related Articles

AI in Observability Has a Context Problem
A recent PulseMeter study conducted by The Futurum Group and Techstrong for NeuBird AI surveyed qualified observability practitioners to understand…

The Category That Can’t Be Ignored: Why the Production Operations Agent Is the Next Frontier in Enterprise AI
By Daniel Day, Chief Marketing Officer, NeuBird AI I’ve spent years in tech marketing, and I’ve learned to distinguish between…