At DevOpsCon San Diego this year the energy was electric and the message was loud and clear: DevOps teams are navigating relentless operational complexity—and they’re looking for AI that actually works in their world. Not AI that lives in a demo, but intelligent automation that fits securely into hybrid environments, accelerates incident response, and helps engineers focus on what matters most.
Across sessions and conversations, the sentiment was strikingly consistent: teams don’t need more dashboards or alerts—they need fewer manual steps and faster root cause clarity.
AI Is Everywhere—But Pragmatism Is Back
AI agents and GenAI were everywhere at the conference, but the buzz was grounded in real-world need. Sessions underscored a shift in mindset: visibility is important—but insight and action are what actually move the needle.
DevOps professionals weren’t chasing the latest AI trend—they were seeking solutions to their most pressing operational challenges. The conversations I had at our booth consistently returned to one theme: how can AI help us work smarter, not harder?
On-Call Burnout Is Boiling Over
Incident response continues to drain DevOps teams. From late-night pings to hours spent tracing pipelines and logs, on-call has become more tedious and time-consuming—even as tooling has improved.
Teams are exhausted from stitching together fragmented telemetry. What they want is AI that understands their stack, integrates into existing systems, and helps get to the root cause faster—without adding another portal or platform to manage.
From Curiosity to Critical Path
Many teams shared past experiments with AI—mostly chatbots or copilots for ticketing or knowledge lookups. Useful, but shallow. Now, the question is different: “Can AI investigate incidents in our production environment without exposing our data?”
Security was a recurring theme. Multiple teams had tried sending telemetry into public LLMs and quickly rolled it back.
One CTO summed it up perfectly: “Dumping production logs into a public LLM isn’t innovation—it’s a liability.”
Sessions that explored successful AI implementation, like Justin Griffin’s real-world story of speeding up deployment investigations with an AI agent, sparked important discussions. During the Q&A, a recurring theme emerged from the audience: teams desperately want AI that can connect the dots between different failure points without requiring them to manually correlate data across multiple tools. As the session demonstrated, the value comes from combining reasoning with context—and doing it securely.
The Security-First AI Revolution
What struck me most about DevOpsCon 2025 was how security considerations are driving better AI adoption, not hindering it. Organizations have learned from early missteps and are now demanding enterprise-grade solutions.
Teams shared cautionary tales of experimenting with general-purpose LLMs—from hallucinated recommendations that caused production outages to security breaches from exposing sensitive telemetry data. The lesson is clear: enterprise operations require purpose-built AI agents, not retrofitted consumer tools.
The Path Forward: Secure, Embedded, Purpose-Built AI
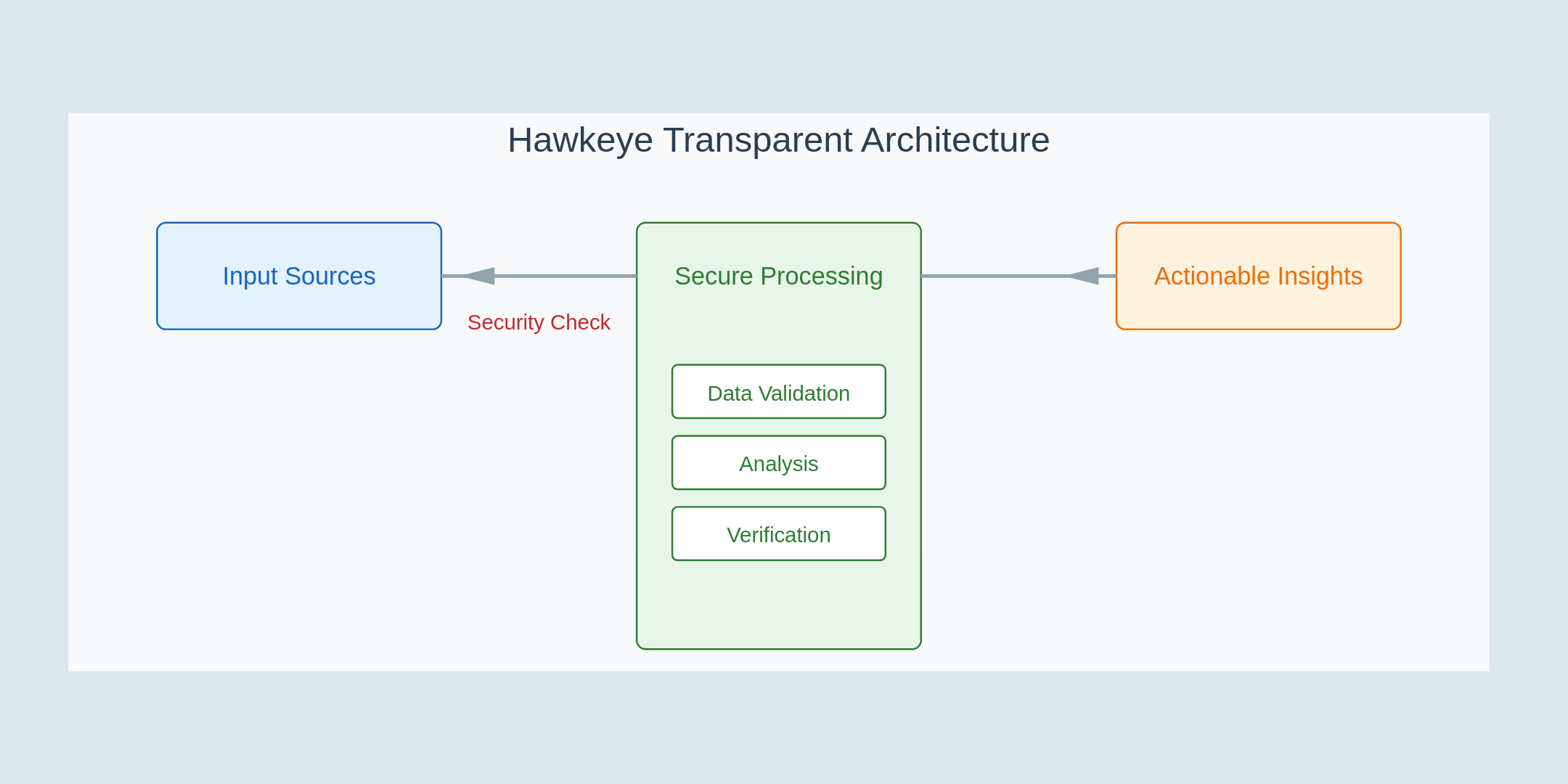
DevOps teams aren’t looking for bolt-on bots or generic copilots. They’re demanding intelligent agents that can integrate deeply with their observability and CI/CD systems, run securely in hybrid environments, and reason through telemetry rather than just summarize it.
That’s why interest in Neubird surged at our booth. Teams saw how it can operate in enterprise environments– cloud-native, on-prem and in hybrid cloud- using chain-of-thought workflows to surface root causes from real telemetry—without ever exposing sensitive data outside of their control.
DevOps Isn’t Getting Simpler—But Your Workflow Can
DevOpsCon 2025 made one thing clear: tool fatigue is real, alert overload is unsustainable, and AI has a critical role to play in restoring signal, trust, and speed.
Engineers aren’t asking AI to replace them. They’re asking for AI that thinks like an expert, works with them, and reduces the operational noise.
If that’s what your team is ready for, let’s connect. 👉 Book a demo to see how Neubird helps reduce MTTR, eliminate redundant work, and bring calm back to your on-call.