Beyond the AI SRE: Operating Production at Enterprise Scale
The enterprises that win the next decade will not automate toil. They will operate production autonomously and measure it by revenue, roadmap, and trust.


The industry is racing to build a better assistant for your on-call engineer. That ambition is too small. The enterprises that win the next decade will not automate toil. They will operate production autonomously and measure it by revenue, roadmap, and trust.
The wrong ceiling
Every few years our industry renames the same hope: that the pager will stop ringing. The latest name is the "AI SRE," a smart assistant that helps your on-call engineer triage a little faster. It is genuine progress. As a category, it is also aiming too low.
If you run production at an enterprise, you do not have a triage problem. You have an operating problem. More than 90 percent of mid-size and large enterprises now say a single hour of downtime costs them over $300,000, and 41 percent put it between $1 million and $5 million. The question your board is asking is not whether MTTR is trending down. It is why your most strategic engineering capacity keeps getting pulled into firefights, and what that is costing the business.
That gap, between automating a task and operating an environment, is the entire story.
An assistant helps. An operator owns the outcome.
An AI SRE is a copilot. It suggests, summarizes, and drafts a runbook while a human stays in the loop on every step. That is useful, but it inherits the same ceiling as the engineer it assists. It scales with headcount. Add more services and more alerts, and you are back to hiring.
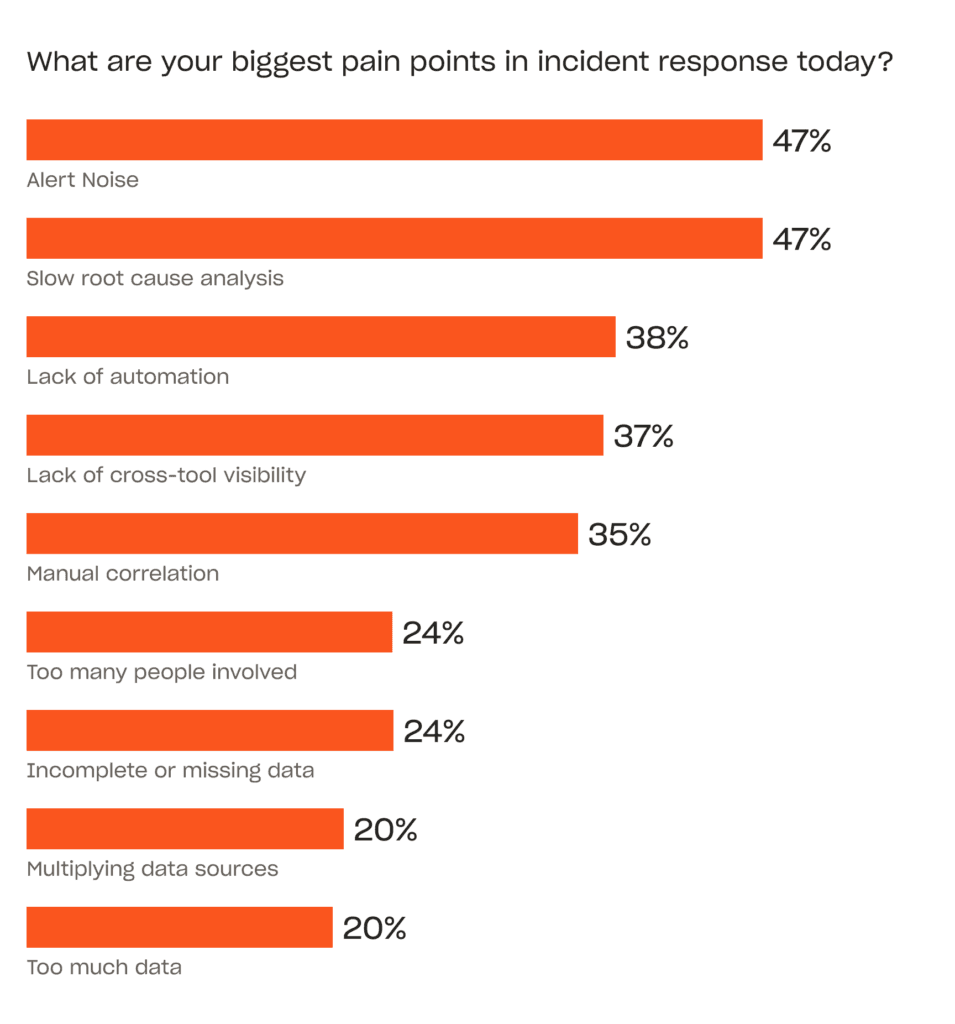
Operating production at scale is a different job. What breaks enterprises is rarely a single dramatic incident. It is the volume: hundreds of services, thousands of signals, and five observability tools that never quite agree. Your engineers spend their nights piecing the story together across all of them, again.
The Production Ops Agent from NeuBird AI is built to operate, not to assist. It investigates across your stack, finds root cause, and handles the work while your team sleeps. Your engineers stop piecing things together across five tools. They wake up to a resolved incident and a clear account of what happened, not a queue of alerts waiting for them to start. The Prod Ops Agent carries the part of the load that does not scale with headcount, which is exactly the part that has been holding your team back.
Picture a Saturday at 2 a.m. A latency spike begins rippling through a payments path. An AI SRE would page your on-call engineer, surface a few correlated alerts, and wait for a human to connect the dots. An operator does the connecting. The Prod Ops Agent traces the spike to its source across services and tools, confirms the root cause, takes the corrective action authorized, and documents the entire chain. Your engineer reads the story in the morning instead of living it overnight.
The real scoreboard is business outcomes
Here is the reframe that matters for anyone who owns production. You are not measured on tickets closed. You are measured on roadmap shipped. Every hour your best engineer spends in a war room is an hour not spent on the work that moves the business forward. When the Prod Ops Agent absorbs the operational load, you get your best people back on the roadmap. That is the outcome leadership actually feels.
Downtime is not an incident count. It is a revenue and competitive-position event. The retailer that goes dark during a launch, the platform that stalls at peak, the service that degrades while a competitor stays up: those are losses you do not recover by trimming a few minutes off mean time to repair. The goal is not a faster cleanup. It is a prevention posture in which the Prod Ops Agent detects the failure pattern and acts before it ever reaches your customer. Keeping production running is the point. Doing it so your engineers do not have to is the difference.
Why scale is the hard part
By 2026, autonomous agents are no longer experimental. They are in production across the enterprise. But most organizations adopted the capability faster than the governance, and agents are non-deterministic by nature. So the hard question at enterprise scale was never whether an agent can take an action. It is whether you can trust it to take that action inside your production environment.
That is a trust problem, and trust is architectural, not aspirational. The Prod Ops Agent is SOC 2 Type II certified, stores no data, operates read-only by design, and leaves a full audit trail of everything it sees and does. That is what makes autonomy safe to run across a real enterprise estate, not just a demo. It deploys live in minutes rather than after a quarter of integration work, and it identifies root cause with 94 percent accuracy, so the actions it takes are grounded in what is actually happening, not a guess.
Scale is also where an assistant and an operator finally diverge. An assistant gets you through tonight. An operator gets better at your environment specifically, every night.
What changes when you operate instead of assist
When you operate production instead of assisting with it, three things change at once, and they are the three things leaders care about. The economics change because the operational load no longer scales linearly with the size of your estate. The roadmap changes, because your best people are no longer the on-call safety net. And the organization changes, because the hard-won knowledge of how your systems actually behave stops walking out the door with every departure. It accumulates in the agent and compounds, so the operating capability you build this year is still yours next year.
This is the shift worth making, and it is bigger than a better assistant for your on-call rotation. It is an agent that keeps your production running, so your engineers do not have to.