The Incident That No Alert Caught: 78% of Teams Have Outgrown Their Monitoring Stack
78% of engineering teams have experienced a failure their monitoring stack missed entirely. That’s not a configuration problem. It’s a sign that enterprise production ops has outgrown the way we run it.
Most engineering teams find out about failures one of two ways: an alert fires, or a customer tells them something is broken. The second one is happening more than anyone wants to admit.
According to NeuBird AI’s 2026 State of Production Reliability and AI Adoption Report, based on a survey of more than 1,000 SRE, DevOps and IT professionals, 78% of organizations have experienced at least one incident where no alert fired at all. Almost 40% of incidents are discovered by customers before the engineering team knows anything is wrong. When the customer is your early warning system, the monitoring stack has a structural problem.
The data makes it clear: Production environments have evolved faster than the systems built to run them.
In VentureBeat’s coverage of the report, they put it plainly: while leadership is writing checks for AI platforms, the technology is often failing to reach the frontline. The result is that engineering teams are spending around 40% of their time on incident management instead of building. That is a gap between investment and impact, and it is showing up in how production environments are actually run.
Increasing Toil: The job that took over the job
Engineering teams are spending a large amount of their time on incident management related tasks. That is time taken away from product development, from designing for reliability, from the work that actually moves systems forward. It goes to reactive work instead. And this figure holds consistent across company sizes. It is not a small-team problem; it is an industry-wide structural condition.
MTTR is the number one KPI cited by 61% of organizations. It is a reasonable metric, but it only starts counting once resolution begins. By then, damage is already done. 93% of organizations pull in at least three engineers when a major incident fires. Each of them is context-switching away from whatever they were building, re-establishing context across a fragmented tooling environment spanning four to seven tools.
There is also a slower-burning cost: burnout. Nearly 40% of organizations report more than a quarter of their on-call engineers are showing burnout symptoms tied to incident management.
When the signal becomes noise
Alert fatigue ranked as the top operational challenge in our survey. Above insufficient automation. Above difficulty identifying root causes.
Alert fatigue used to be a morale problem. Now it is a reliability risk. When 70% of alerts don’t require action, engineers adapt and stop treating every alert as urgent. That is simply pattern recognition. The problem is what gets missed when the pattern breaks.

Source: 2026 State of Production Reliability and AI Adoption Report, NeuBird AI
44% of organizations experienced an outage in the past year directly linked to an ignored or suppressed alert. And 78% experienced at least one incident where no alert fired at all.
When customers are finding failures before the monitoring system does, the monitoring system is no longer an early warning system. It is just generating noise.
Leadership and practitioners are describing different realities
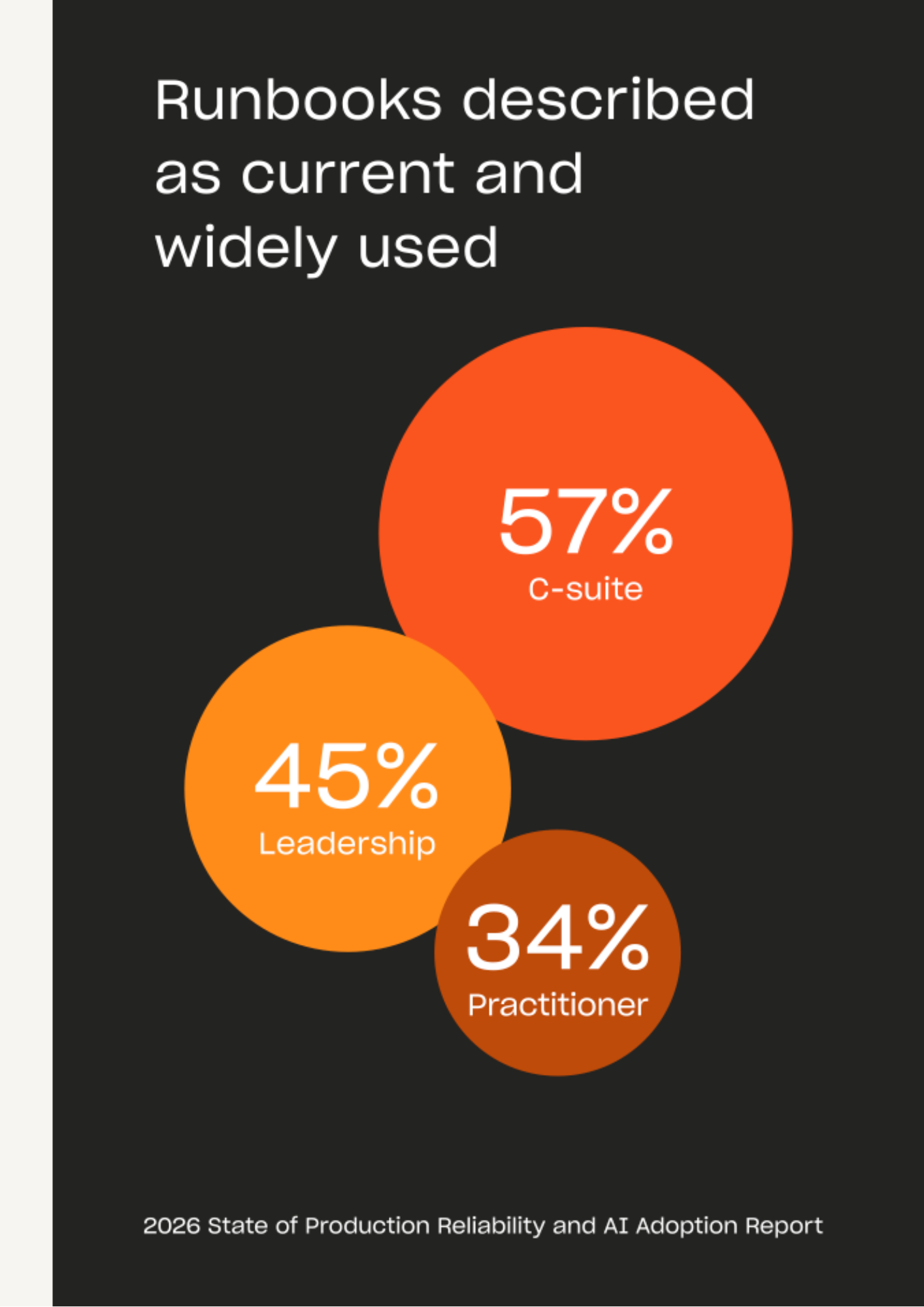
What production operations looks like when the cycle breaks
The more time teams spend on reactive incident work, the less time they have to design and build systems for better reliability. Unresolved root causes generate recurring failures. The cycle feeds itself and compounds over time. Faster response helps, but it does not break the cycle.
What comes next is not a better alerting tool. It is a shift in how production operations are fundamentally run. From responding after the fact to identifying risk before impact, and towards autonomous systems that correlate, investigate and act.
NeuBird AI customers have resolved over 1 million alerts, saved over $2 million in engineering hours, and achieved up to 90% reduction in MTTR. The latest release of NeuBird AI introduces Preventive Risk Insights, moving teams from incident resolution into continuous risk detection before failures affect production.
The 40% of engineering capacity consumed by reactive work highlights that the systems teams rely on today were built for a different era of infrastructure complexity. That era is over.
NeuBird AI replaces that model with an autonomous production ops agent that prevents issues before they surface, resolves the ones that do in minutes, and continuously optimizes operations so that incident volume trends down over time. This finally breaks the cycle. It is how production operations keep pace with the infrastructure they are built to run.
Check out the 2026 State of Production Reliability and AI Adoption Report to see the complete findings, or book a demo to see NeuBird AI’s autonomous production ops agent in practice.
Written by

Shilpi Srivastava
Marketing @ NeuBird AI
Related Articles

What is a Production Ops Agent?
An explainer, with personalities Somewhere in your company right now, an engineer is staring at a Slack channel full of…

Skills Are Going Viral Across AI Agents – Here’s How We Built an Enterprise Hub for Production Ops
Introducing FalconClaw: curated, secure, and compatible with 31,000+ OpenClaw community skills. The most capable AI agents today — coding assistants,…