AI Agents vs LLMs for SRE: Why Enterprises Need Both
Why enterprise SRE requires purpose-built AI agents, not raw LLMs: orchestration, governance, iterative reasoning, and domain-specific knowledge.

Every few months, I get asked the same question, sometimes by investors, sometimes by prospects, and sometimes by deeply curious engineers: “Why do we need an agent****? Can’t I just ask Claude or GPT to look at my logs or dashboards and tell me what’s wrong?” That question is really about AI agents vs LLMs for SRE: whether a raw model can do the job, or whether you need an agent built around it. On the surface, it’s a fair question. Ask these models almost anything and they’ll generate a convincing - sometimes even correct - answer. It’s tempting to imagine that with the right prompt, you can have an AI Sherlock Holmes on your team, ready to sift through logs, spot anomalies, and pinpoint root causes on demand. But this perspective on LLMs, while understandable, oversimplifies what's needed in enterprise environments. After years building and scaling enterprise infrastructure, I've learned that this fantasy crumbles under the weight of reality. Let me explain why.
What Problems Do AI SRE Platforms Solve?
Before weighing AI agents vs LLMs for SRE, it helps to name the problems an AI SRE platform actually solves. Enterprise operations teams drown in telemetry, juggle dozens of tools, and burn out on-call engineers chasing incidents across systems that don’t talk to each other. A Production Ops Agent platform tackles that head-on. It answers the questions teams struggle to answer fast enough on their own:
- Which of the terabytes of daily telemetry actually matters to this incident?
- Where is the root cause hiding across logs, metrics, traces, and configs?
- How do we investigate without violating access controls or compliance boundaries?
- How do we cut mean time to resolution when every minute maps to an SLA?
A raw LLM answers none of these on its own. An AI agent, purpose-built for SRE work, does. That distinction is the whole point of AI agents vs LLMs for SRE, and the rest of this post breaks down why.
The Enterprise Reality Check
1. You Need the Right Data, Not All the Data
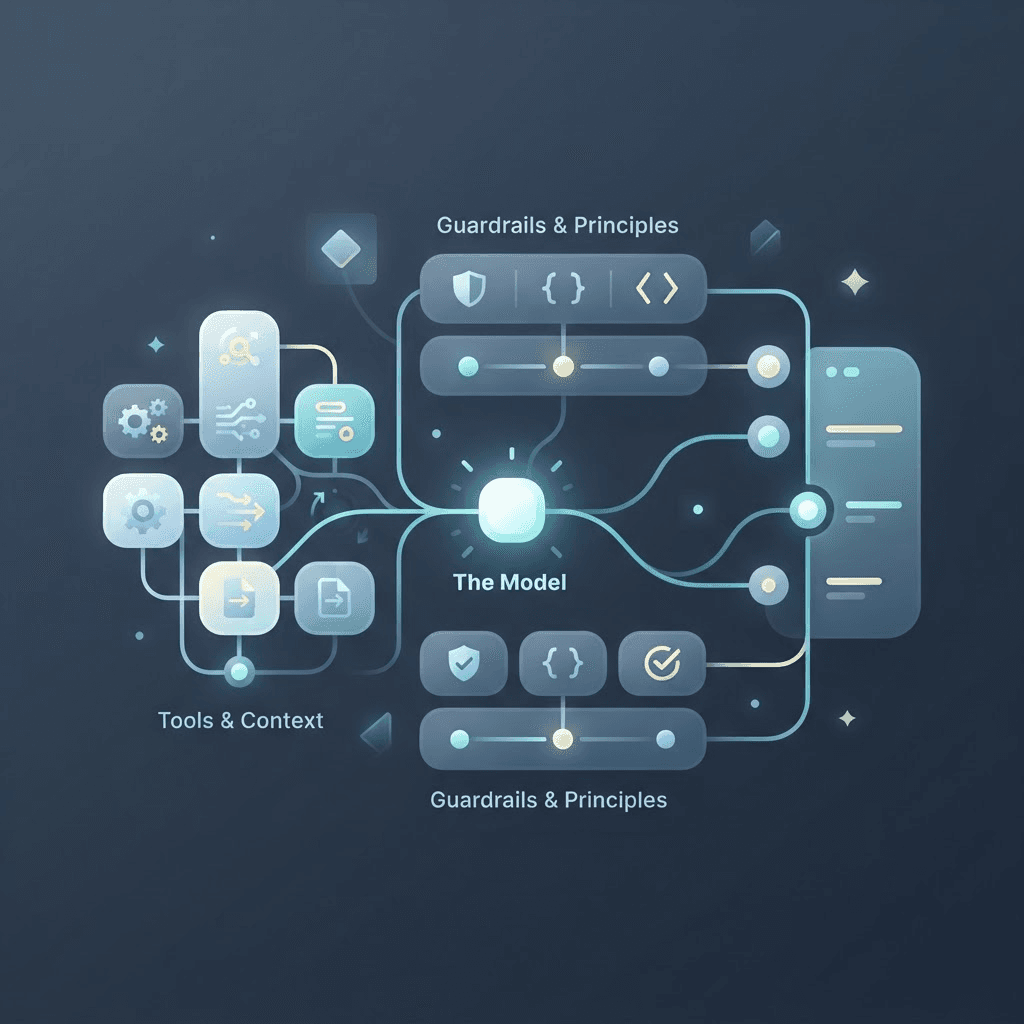
A typical enterprise generates terabytes of telemetry daily: metrics, logs, traces, events, configs, and tickets across hundreds of services and teams. No LLM, not even GPT-4 Turbo with its expanded context window, can reason over this firehose in one go. When an SRE asks a question like “Why did latency spike in the checkout service at 2 AM?”, the answer doesn’t lie in all your logs. It lies in a few very specific pieces of information, scattered across multiple tools and sources. An agent needs to know what data to fetch, where to fetch it from, and how to filter it down to what matters, before any reasoning even begins. That’s not just an LLM prompt; it’s an orchestration problem.
2. Governance and Access Control Are Non-Negotiable
In the enterprise, data access is gated. For good reason. Teams have different levels of access. Some logs may contain sensitive credentials, PII, or customer data. You can’t just scoop all that into a cloud LLM, nor should you. Any AI system operating in this environment must respect governance boundaries. That means role-based access, audit trails, and data isolation, all things you won’t get by copy-pasting into an off-the-shelf LLM.
3. Effective Troubleshooting Requires Iterative Reasoning
Even when you have the right data, real troubleshooting is not a one-shot process. It’s a loop.
- Ask a question
- Sample some data
- Reason about what you saw
- Realize you need more context
- Go fetch more
- Repeat until clarity emerges
This is where a well-designed AI agent shines, and where the gap between AI agents vs LLMs for SRE is widest. It wraps the LLM in an iterative loop: a structured reasoning engine that can interact with systems, query APIs, follow hunches, and converge on an answer. At NeuBird AI, we call this the thinking loop, and it’s the foundation of how our AI SRE agent works.
Image. “The Thinking Loop”- Iterative Reasoning Process.
4. Domain-Specific Reasoning - the Missing Ingredient
Our agent, isn’t just smart. It’s trained to think like an SRE. It follows runbooks, just like humans do. These aren’t static scripts. They’re dynamic workflows built from the collective expertise of professionals who’ve managed infrastructure for years. At NeuBird AI, we’ve distilled decades of domain knowledge into these runbooks. They guide the agent’s decision-making: when to look at pod-level logs, when to check autoscaler behavior, when to cross-check a spike against a recent Terraform apply. What makes these runbooks special is how they function as reasoning guides for LLMs. Rather than drowning LLMs in raw data, we deploy these reasoning engines surgically, with runbooks providing the essential context. This targeted approach helps extract the best analytical power from LLMs while adding the domain-specific knowledge they inherently lack. LLMs can’t learn that from first principles. They need scaffolding. They need rules. They need the wisdom of people who’ve done this work for a living. That’s what we build into the agent.
5. Connections Across Multiple Enterprise Data Sources
Most IT teams operate with a complex ecosystem of observability tools, each pulling from diverse data sources. The answer to critical infrastructure questions doesn't reside in a single log file. It's scattered across multiple tools and sources. An effective agent needs to know what data to fetch, where to find it, and how to filter it down to what matters, before reasoning can even begin. This isn't just a prompt engineering challenge; it's an orchestration problem requiring reliable, enterprise-sanctioned connections to your data infrastructure.
6. DIY Projects Are Fun, Until They’re Not
Yes, you can prototype a toy version of this. You can wire up ChatGPT to your Datadog logs or pipe some traces into Claude and get a flashy demo. I’ve seen it. I’ve done it. But that’s not a production-grade system. Real-world systems have:
- 20+ sources of telemetry
- Multi-team permissions
- On-call workflows
- Compliance constraints
- SLAs tied to minutes
Building an agent that works across all of that? That’s not a weekend project. That’s a multi-year, cross-functional engineering challenge, and one that NeuBird AI has chosen to take on so our customers don’t have to. Read more: Our from the trenches insights on ITOps from SREcon 2025
The Bottom Line
LLMs are tools. Powerful ones. But they are not solutions by themselves. In the world of IT and SRE, where context is everything and stakes are high, you need more than just generative language. You need generative operations. That’s what we’re building at NeuBird AI. An agent that doesn’t just answer questions, but solves problems.