Taming the Error Flood: How Neubird Makes Sense of Application Chaos
How SRE teams are transforming error analysis with Neubird's AI-powered platform to quickly identify patterns and root causes across distributed systems.

How SRE teams are transforming error analysis with Neubird
Your monitoring dashboard explodes with alerts as your web application in the 'checkout' namespace starts generating a torrent of errors. CloudWatch is capturing every error, your APM solution is tracking every failed request, and Prometheus metrics show increasing error rates - but with different error types, status codes, and messages flooding in, finding the signal in this noise feels like trying to drink from a fire hose.
The Modern Error Analysis Challenge
In today's microservices environments, error investigation occurs within sophisticated observability stacks. Your APM solution traces every request, CloudWatch captures detailed error logs, Prometheus tracks error metrics, and your logging platform aggregates errors across services. Yet when error floods occur, this wealth of information often obscures rather than illuminates the root cause. A typical investigation unfolds across multiple systems: You start in your APM tool, watching transaction traces light up with errors. The service dependency map shows cascading failures, but which service triggered the cascade? Switching to CloudWatch, you wade through error logs trying to identify patterns. Each log entry adds more context but also more complexity - different error types, varying stack traces, and multiple affected components. The investigation branches out as you attempt to correlate data:
- APM traces show increased latency preceding the errors
- Prometheus metrics indicate growing error rates across multiple services
- Kubernetes events reveal pods restarting due to failed health checks
- Load balancer metrics show increased 5xx responses
- Individual service logs contain different error messages and stack traces
Each tool captures a piece of the puzzle, but understanding how these pieces fit together requires constantly switching contexts and mentally correlating events across different services, timelines, and abstraction layers.
Why Error Floods Challenge Traditional Analysis
What makes error flood analysis particularly demanding isn't just the volume of errors - it's understanding the relationships and root causes across a distributed system. Error patterns often manifest in complex ways: An error in one microservice might trigger retry storms from dependent services, amplifying the error rate. Rate limiting kicks in, causing a new wave of errors with different signatures. Circuit breakers trip, changing the error patterns yet again. Each layer of your reliability mechanisms, while protecting the system, also transforms the error signatures and complicates the analysis. Your observability tools dutifully record every error, metric, and trace, but understanding the sequence of events and cause-effect relationships requires simultaneously analyzing multiple data streams while understanding service dependencies, reliability patterns, and failure modes.
Neubird AI SRE: Your Error Analysis Expert
Here's how Neubird transforms this investigation:
The Neubird Difference
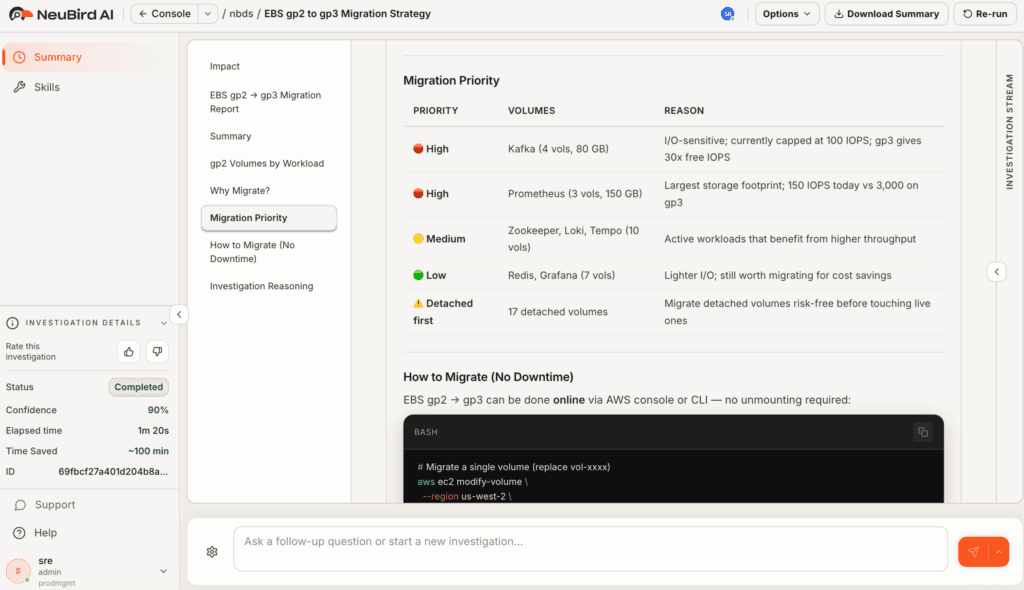
What sets Neubird apart isn't just its ability to aggregate errors - it's how it analyzes error patterns across multiple observability systems simultaneously. While an SRE would need to manually correlate data between APM traces, error logs, metrics, and service dependencies, Neubird processes all these data streams in parallel to quickly identify patterns and causality chains. This parallel analysis capability allows Neubird to discover cause-and-effect relationships that might take hours for humans to uncover. By simultaneously examining service behavior, error patterns, and system metrics, Neubird can trace how an error in one component cascades through your entire system. Read more: Discover how SRE teams are evolving their Kubernetes dashboard observability with AI.
Real World Impact
For teams using Neubird, the transformation goes beyond faster error resolution. Engineers report a fundamental shift in how they approach system reliability: Instead of spending hours correlating data across different monitoring tools during incidents, they can focus on implementing systematic improvements based on Neubird's comprehensive analysis. The mean time to resolution for error floods has decreased dramatically, but more importantly, teams can prevent many cascading failures entirely by acting on Neubird's early warnings and recommendations.
Implementation Journey
Integrating Neubird into your Kubernetes environment is straightforward:
- Connect your existing observability tools - Neubird enhances rather than replaces your current monitoring stack
- Configure your preferred incident response workflows
- Review Neubird’s incident analysis, drill down with questions, and implement recommendations.
Scale your team and improve morale by transforming your approach to application debugging from reactive investigation to proactive improvement. Let Neubird handle the complexity of taming the error flood while your team focuses on innovation. Book a demo or contact us to learn more.