Rewriting Incident Response: The $400B Case for Going Autonomous
Downtime costs Global 2000 companies $400 billion yearly. Autonomous RCA addresses delayed incident diagnosis and manual recovery workflows that waste time.

Downtime is costing Global 2000 companies $400 billion a year¹. That’s not just a technical concern: it’s a direct hit to revenue, reputation, and resilience. A major contributor to that cost is what happens after an incident begins: delayed root cause analysis, misdirected investigations, and manual recovery workflows that burn time and stall progress. Even with modern observability in place, diagnosing the issue and responding quickly remains one of the most time-consuming, error-prone tasks in IT. That’s the big gap where autonomous response can drive the biggest impact.
The Real Cost of Manual Root Cause Analysis
Most teams today rely on four or more observability platforms² ³, yet incident diagnosis remains the top challenge for SREs. That gap between visibility and action has very real consequences:
- Downtime costs scale quickly. SLA penalties, overtime, and lost productivity add up, especially when teams are pulled into extended triage loops.
- Teams fix symptoms, not causes. Quick patches often target surface-level issues. When the root cause goes untreated, incidents recur, or trigger entirely new ones downstream.
- Misdirected investigations stall recovery. Infra teams may suspect application errors, while app teams chase infrastructure bugs. Entire teams can burn days debugging the wrong layer.
- Engineering time gets swallowed by ops. Instead of building the next release, developers spend hours in postmortems and root cause hunts, delaying delivery and draining morale.
One platform team we worked with spent over a week chasing what they thought was an application issue. When they brought in Neubird our AI SRE agent, it found the real cause (a misconfigured readiness probe causing cascading pod restarts) and recommended a fix in under four minutes. This isn’t an edge case. It’s the norm in modern enterprise systems.
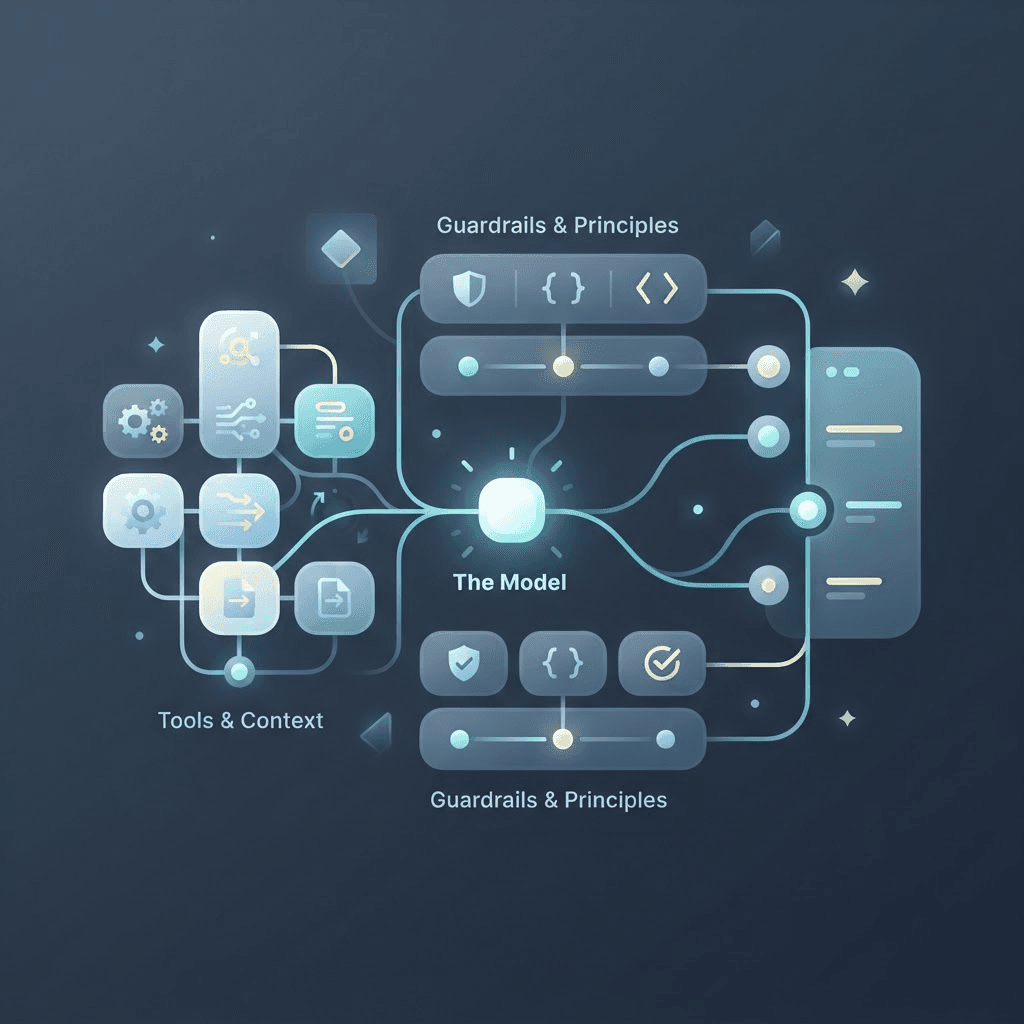
Modern ITOps Needs Autonomous Investigation
Today’s enterprise environments are complex: spanning cloud services, containerized applications, microservices, and legacy systems. As these systems grow and change constantly, diagnosing incidents has only become harder. Teams are overwhelmed, not by lack of data, but by the time it takes to interpret it. The alert volume is high and context is fragmented across systems. This is why incident response must evolve, from reactive analysis to intelligent automation. We built Neubird to act as an agentic AI teammate for IT operations teams. It doesn’t just summarize data. It investigates incidents from the moment they’re triggered: correlating telemetry, analyzing dependencies, and identifying the most probable root cause. It then recommends targeted remediations and proactive steps to prevent recurrence. This isn’t replacing your engineers. It’s returning their time, accelerating RCA, and removing the manual drag that slows down every release.
Building Agentic Workflows into the Stack You Already Use
Adopting autonomous response shouldn’t require ripping out your existing stack. In fact, success depends on embedding intelligent agents into the workflows your teams already trust, without creating new silos or operational overhead. Engineering and platform leaders should prioritize solutions that:
- Integrate natively with your observability, monitoring and incident management systems
- Are built with enterprise governance and security in mind
- Deliver insight where teams already work, whether that’s in Slack, Datadog, PagerDuty, or elsewhere
Building agentic workflows means enabling real-time diagnosis without additional dashboards and without duplicating telemetry. That’s how you create impact without disruption. Read more: The autonomous investigation space is growing fast. For a breakdown of which platforms actually deliver cross-tool RCA vs. which stop at alert correlation, see our AI SRE tools comparison.
From Reactive to Resilient
Manual triage doesn’t scale. It burns hours, stalls recovery, and pulls engineers away from higher-impact work. The more incidents you resolve manually, the more velocity you lose. With autonomous investigation in place, every resolved incident becomes time returned to the roadmap. And when you reclaim that time across your SRE and IT operations team supporting critical systems, you’re not just optimizing workflows. You’re cutting directly into the hidden costs of downtime.
The Shift to Autonomous Operations Has Begun
The old model (alert floods, manual triage, constant firefighting) can’t keep up with the speed and scale of modern IT. What teams need now is precision: Faster answers. Real root cause. Fewer distractions. This is the shift autonomous investigation enables: From chasing symptoms to solving problems at the source. From reacting under pressure to resolving with confidence. From operational drag to engineering momentum. The future of IT operations is autonomous, and it’s already within reach. Sources: ¹ Splunk, The Hidden Costs of Downtime 2 Grafana Labs Observability Survey 2024 3 Catchpoint The SRE Report 2024