When Pods Won't Scale: How Neubird Solves Kubernetes Capacity Challenges
Learn how Neubird's AI SRE Agent solves Kubernetes scaling challenges by analyzing capacity constraints across multiple infrastructure layers simultaneously.

How SRE teams are eliminating scaling headaches with Neubird
It's peak holiday shopping season, and your e-commerce platform is experiencing record traffic. Your team initiates a scaling operation to handle the load, increasing the UI deployment's replica count. But instead of scaling smoothly, pods remain stuck in pending state. The PagerDuty alert sounds: "Maximum pod_status_pending GreaterThanThreshold 0.0". What should be a routine scaling operation has become a critical incident requiring deep investigation across multiple layers of your Kubernetes infrastructure.
The Modern Scaling Investigation Reality
In today's Kubernetes environments, scaling issues occur within sophisticated observability stacks. CloudWatch captures detailed node and pod metrics while recording scheduler decisions. Prometheus tracks resource utilization, and your APM solution monitors service performance. Yet when scaling problems arise, this wealth of information often complicates rather than simplifies the investigation. A typical troubleshooting session spans multiple systems and contexts: You start in Prometheus, examining node capacity metrics. Resources seem available at the cluster level, but are they accessible to your workload? Switching to CloudWatch Container Insights, you dive into pod-level metrics, trying to understand resource utilization patterns. Your logging platform shows scheduler events, but the messages about resource pressure don't align with your metrics. The investigation expands as you correlate data across systems:
- Node metrics show available capacity
- Pod events indicate resource constraints
- Scheduler logs mention taint conflicts
- Prometheus alerts show resource quotas approaching limits
- Service mesh metrics indicate traffic distribution issues
Each tool provides critical information, but understanding how these pieces fit together requires constantly switching contexts and mentally correlating events across different abstraction layers in your Kubernetes stack.
Why Scaling Challenges Defy Quick Analysis
What makes scaling investigation particularly demanding isn't just checking resource availability - it's understanding the complex interaction between different layers of Kubernetes resource management and constraints: Available CPU and memory might look sufficient at the cluster level, but pod anti-affinity rules could prevent optimal placement. Node selectors and taints might restrict where pods can run. Resource quotas at the namespace level might block scaling even when node capacity is available. Quality of Service classes affect pod scheduling priority, and Pod Disruption Budgets influence how workloads can be redistributed. Your observability tools faithfully record all these metrics and events, but understanding the sequence and cause-effect relationships requires simultaneously analyzing multiple data streams while understanding Kubernetes scheduling logic, resource management, and workload distribution patterns.
Neubird: Your Scaling Expert
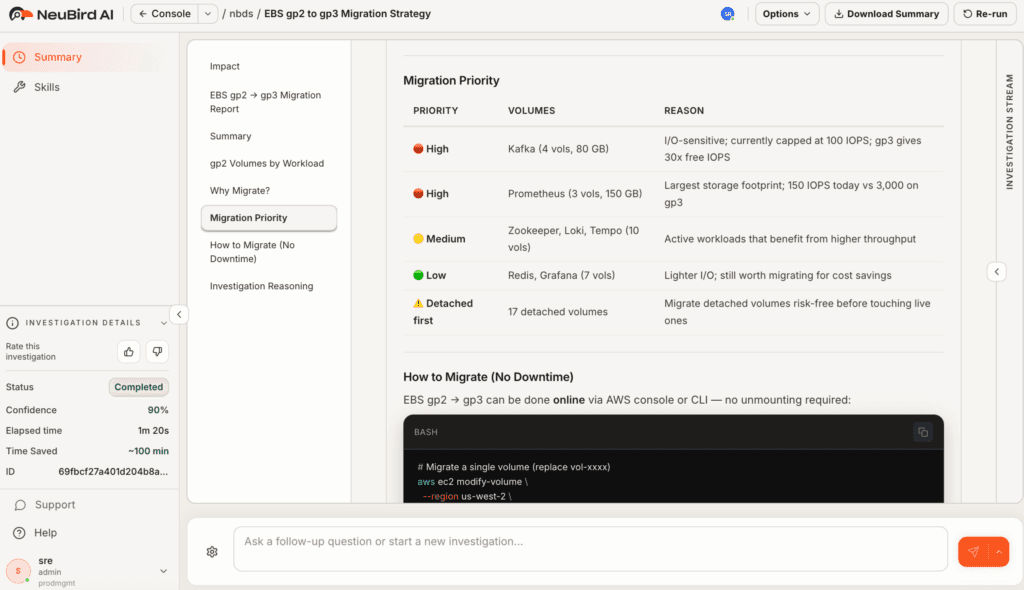
Here's how Neubird transforms this investigation:
****
The Neubird Difference
What sets Neubird apart isn't just its ability to check resource metrics - it's how it analyzes capacity constraints across multiple layers of your Kubernetes infrastructure simultaneously. While an SRE would need to manually correlate data between node metrics, scheduler logs, pod events, and cluster configurations, Neubird processes all these data streams in parallel to quickly identify bottlenecks and constraints. Read more: Scaling challenges often appear first in dashboards, but traditional monitoring has its limits. Discover how AI can enhance your Kubernetes dashboards to predict scaling issues before they occur. This parallel analysis capability allows Neubird to discover cause-and-effect relationships that might take hours for humans to uncover. By simultaneously examining node capacity, scheduling rules, workload distribution patterns, and historical scaling behavior, Neubird can identify subtle constraints that wouldn't be apparent from any single metric or log stream. How NeuBird AI handles Kubernetes incidents →
Real World Impact
For teams using Neubird, the transformation goes beyond faster scaling incident resolution. Engineers report a fundamental shift in how they approach capacity management: Instead of spending hours correlating data across different monitoring tools during scaling incidents, they can focus on implementing systematic improvements based on Neubird's comprehensive analysis. The mean time to resolution for scaling-related incidents has decreased dramatically, but more importantly, teams can prevent many scaling bottlenecks entirely by acting on Neubird's early warnings and recommendations.
Implementation Journey
Integrating Neubird into your Kubernetes environment is straightforward:
- Connect your existing observability tools - Neubird enhances rather than replaces your current monitoring stack
- Configure your preferred incident response workflows
- Review Neubird’s incident analysis, drill down with questions, and implement recommendations.
Scale your team and improve morale by transforming your approach to application debugging from reactive investigation to proactive improvement. Let Neubird handle the complexity of pod_status_pending analysis while your team focuses on innovation. See NeuBird's full Kubernetes SRE solution. Follow Neubird![]()