How Context Engineering Separates Enterprise AI from Toy AI SRE Agents
Context engineering separates enterprise AI from toy SRE agents. Learn how structured, relevant context transforms raw telemetry into actionable insights for production environments.


In the age of LLMs, it’s easy to build an AI agent that can do something. Wire up a prompt, call an API, and the demo looks great. It feels impressive - until you try to run it inside a real enterprise environment. Because in enterprise environments, doing something isn’t enough. These environments are chaotic: telemetry is noisy, systems are fragmented, and stakes are high. In this world, most AI agents collapse under pressure. Why? Because they lack one critical capability: contextual understanding. The difference between a toy agent and one that performs under pressure comes down to a single idea: context. And in production, context doesn’t come from a prompt. It comes from context engineering - a discipline most teams are only beginning to understand.
Most Agents Don’t Fail Because the Model Is Weak
They fail because the context is. LLMs are capable of advanced reasoning - but only when you feed them the right inputs. In enterprise IT, that’s no small feat. You’re dealing with:
- Unstructured, deeply nested logs
- High-volume, high-dimensional metrics
- Distributed traces across async systems
- Alerts based on thresholds, not causality
- Constantly changing configs
Feed that into a model naively, and you don’t get insight. You get noise.
What Is Context Engineering?
Context engineering is the discipline of transforming raw data into structured, relevant, and task-specific input for an AI agent. It’s about designing what the agent should see - and more importantly, what it shouldn’t. It's about curating the right data, in the right format, at the right time. That includes:
- Pulling the right logs, not just the most recent ones
- Extracting signal from high-volume metrics without flooding the model
- Aligning traces, configs, and events into coherent timelines
- Framing input to reflect how real engineers debug incidents
It’s surgical. And it’s what enables agents to reason instead of react.
Why This Matters for Enterprise AI Agents
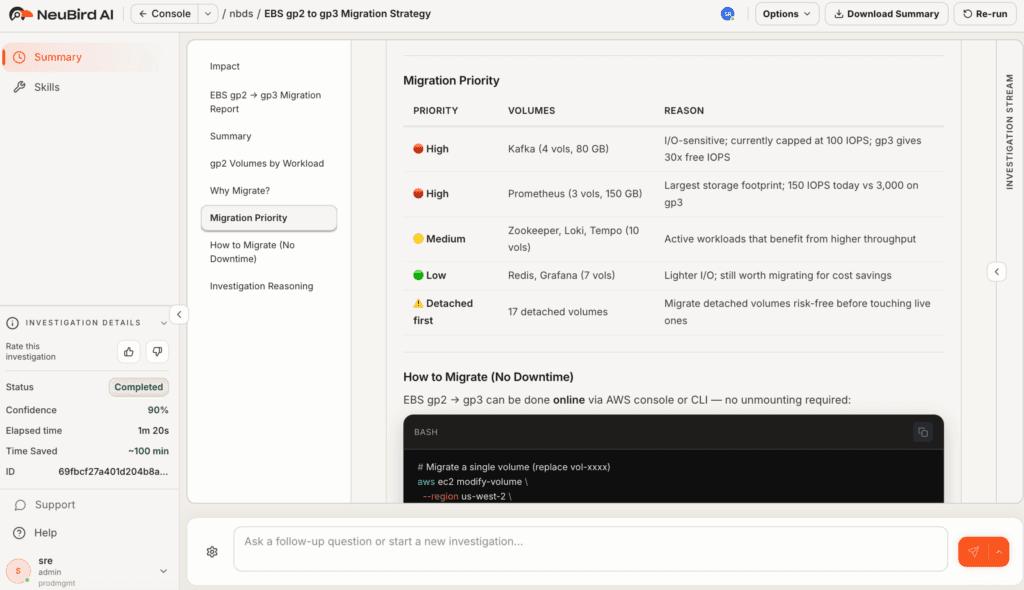
Agents that operate in production environments need more than LLM wrappers and chatbot UIs. They need the ability to trace causality across signals, awareness of architecture and deployment shifts, and contextual reasoning that mirrors how SREs think under pressure. This requires more than a model. It requires a context engine: a system that filters, aligns, and sequences telemetry to make reasoning possible. At NeuBird, this principle shaped how we built our AI SRE agent. And it’s the foundation for what we believe all enterprise-grade agents will need to evolve: with context as the first-class input, not an afterthought.
Context Engineers: The Builders Behind the Curtain
This shift demands a new kind of builder: the context engineer. Context engineers aren’t prompt tuners or ML ops specialists - they’re systems thinkers. For enterprise IT operations, these would be people who’ve been on-call, traced issues across stacks, and know what real production debugging looks like. They build pipelines that:
- Curate high-value context from raw telemetry
- Normalize inputs across heterogeneous systems
- Model the investigative paths that SREs actually follow
- Translate infrastructure knowledge into structured, machine-readable form
They’re not just enabling the agent to respond. They’re teaching it to think.
Enterprise AI Will Be Built on Context
Everyone’s racing to build agents. But very few are building ones that truly understand the enterprise. If your agent isn’t context-aware, it’s just reacting to symptoms. If it can’t reason across telemetry, it’s not doing RCA. If it doesn’t have engineered context, it’s not ready for production. Read more: We used context engineering as one of six evaluation criteria in our AI SRE Tools guide. The divide is clear: platforms that query live telemetry at investigation time vs. those working from pre-indexed snapshots produce fundamentally different results. The future of enterprise AI will be shaped not by who uses the biggest model - but by who delivers the most relevant, structured, and actionable context to it. That’s context engineering. And that’s what makes the difference between a great demo and an enterprise grade agent. Read more: Once context is engineered, reasoning graphs document the full decision chain, creating institutional knowledge from every investigation.