Beyond Retry Logic: Mastering Step Functions Error Handling for Mission-Critical Workflows
Learn how to master AWS Step Functions error handling beyond basic retry logic. Discover how Neubird's AI SRE transforms mission-critical workflow reliability.

Tired of those 3 AM wake-up calls caused by failed Step Functions workflows?
It's 3 AM, and your phone lights up with another alert. A critical Step Functions workflow has failed, affecting customer orders worth millions. You dive into CloudWatch logs, trying to piece together what went wrong. Was it a timeout in that Lambda function? Did the downstream API fail? Maybe it's related to that deployment from yesterday? As you switch between multiple browser tabs (CloudWatch metrics, logs, dashboards, ServiceNow tickets, deployment logs) you can't help but think: "There has to be a better way." This scenario plays out in organizations every day, where Step Functions orchestrate mission-critical workflows processing millions of transactions. While Step Functions itself is incredibly reliable, the complexity of distributed workflows means that error handling and recovery remain significant challenges for even the most experienced SRE teams. At Neubird, we understand the frustration and pressure that comes with managing mission-critical workflows in the cloud. Neubird allows teams to move from reactive troubleshooting to proactive optimization, fundamentally changing how they operate. Not convinced? Let's illustrate Neubird's transformative capabilities with a real-world example. Care to learn more? Continue reading.
The Hidden Complexity of Modern Workflows
Today's Step Functions workflows are far more complex than simple linear sequences. They typically involve:
- Multiple Lambda functions with diverse runtime characteristics: Each function may have unique resource requirements and potential points of failure. For example, a memory-intensive function might be more prone to timeouts than a CPU-bound function.
- Integration with various AWS services: Interactions with services like SQS, DynamoDB, and SageMaker introduce dependencies and potential error sources. Imagine a workflow where a Lambda function reads data from an SQS queue, processes it, and then writes the results to a DynamoDB table. A failure in any of these services can cause the workflow to fail.
- Third-party API calls with varying reliability: External APIs can be unpredictable, with varying response times and error rates. For instance, an API call to a payment gateway might fail intermittently due to network issues or rate limiting.
- Complex branching logic and parallel executions: Workflows with intricate logic and parallel paths can be challenging to debug when errors occur, especially when a failure in one part of the workflow might be triggered by an issue in a seemingly unrelated part due to hidden dependencies.
- Data transformations and state management: Managing data flow and state across different steps adds another layer of complexity to error handling. If a data transformation step fails, it can corrupt the data and cause subsequent steps to fail.
- Cross-region and cross-account operations: Distributed workflows spanning multiple regions or accounts introduce additional challenges for tracking and resolving errors. For example, if a workflow invokes a Lambda function in a different region, network latency or regional outages can cause failures.
When something goes wrong, the challenge isn't just identifying the failed step; it's understanding the entire context. Did retries exhaust because of a temporary network issue? Is there a pattern of failures during peak load? Are timeout configurations appropriate for current processing volumes? Learn more from AWS.
The Limitations of Traditional Approaches to Step Function Retry Logic
Current error handling strategies often rely on: Basic retry configurations within AWS Step Functions: While Step Functions provides built-in retry mechanisms, these are often insufficient for handling complex failure modes. These mechanisms include configuring retriers with options like "Interval" to specify the time before the first retry, "Max attempts" to limit the number of retries, and "Backoff rate" to control how the retry interval increases with each attempt. However, these basic configurations may not be enough to address intricate failure scenarios, such as when a Lambda function fails due to a dependency on a third-party API that is experiencing intermittent outages. At Neubird, we've encountered numerous situations where basic retry logic simply wasn't enough. Catch states with simple error routing: Catch states can redirect workflow execution upon error, but they may not provide enough context for effective remediation. For example, a catch state might simply log the error and terminate the workflow, without providing insights into the underlying cause or suggesting potential solutions. CloudWatch alarms on failure metrics: Alarms can notify you of failures, but they often lack the granularity needed to pinpoint the root cause. Read how Neubird AI SRE can transform your CloudWatch ServiceNow integration for more ideas. Manual investigation of execution histories: Manually reviewing execution histories can be time-consuming and inefficient, especially for complex workflows with numerous steps and branches. Custom logging solutions: While custom logging can provide valuable insights, it often requires significant development effort and may not be comprehensive enough. While these approaches work for simple scenarios, they fall short when dealing with complex failure modes:
- Hidden Dependencies: A timeout in one branch of a parallel execution might stem from resource contention in another branch, making it difficult to identify the true root cause.
- Cascading Failures: Retry storms, where a failed step triggers a cascade of retries across dependent services, can overwhelm downstream systems and exacerbate the problem. For instance, if a Lambda function fails and retries repeatedly, it might flood an SQS queue with messages, causing delays and potentially impacting other workflows that depend on that queue.
- Inconsistent State: Failed workflows can leave systems in an inconsistent state, requiring manual intervention to restore data integrity and resume operations.
- Alert Fatigue: Generic failure alerts provide minimal context, leading to alert fatigue and delayed responses. If you receive a generic alert that simply states "Step Functions workflow failed," it doesn't give you much information to work with, and you might be tempted to ignore it if you're already dealing with numerous other alerts.
Furthermore, it's important to understand how Step Functions handles retries in the context of "redriven executions" (where a failed execution is restarted). When a redriven execution reruns a task or parallel state with defined retries, the retry attempt count for those states is reset to 0. This ensures that the maximum number of retries are still allowed, even if the initial execution had already exhausted some retry attempts.
Transforming Error Handling with Neubird AI SRE: Beyond Basic Step Function Retry
Imagine walking in tomorrow to find:
- Detailed analysis of failure patterns already completed
- Correlated events across your entire AWS environment
- Precise identification of root causes
- Recommended configuration adjustments
- Automated recovery for known failure patterns
This isn't science fiction. It's what leading SRE teams are achieving with Neubird as their AI-powered teammate.
The Neubird Difference: A Real-World Investigation of Step Function Retry and Catch
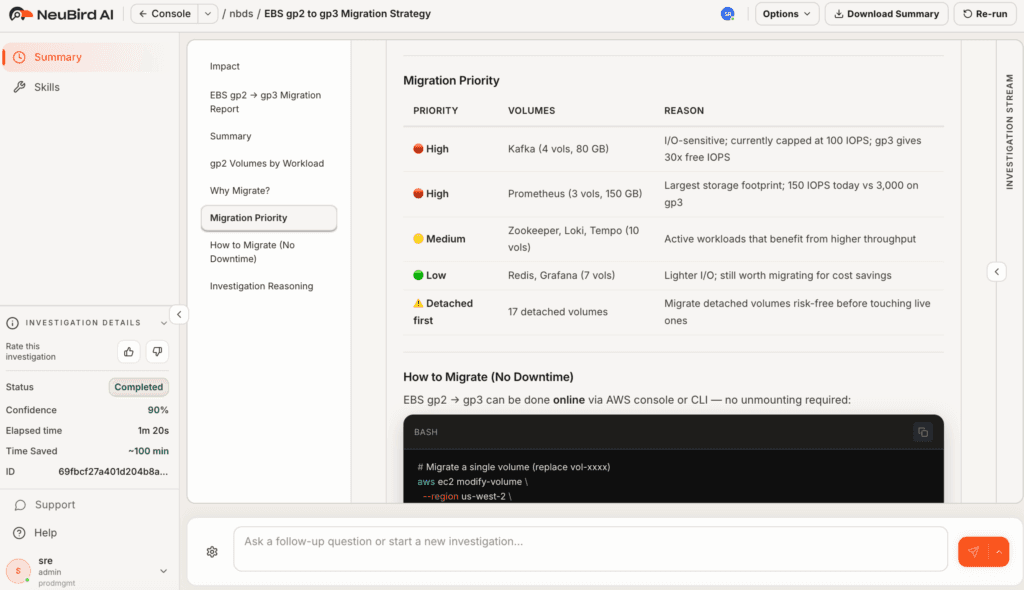
Following up on the real-world example. An e-commerce platform's critical order processing workflow began failing intermittently during peak hours. The Step Functions execution showed a series of Lambda timeouts, leading to failed customer transactions and a growing support queue. Here's how Neubird analyzed the incident: When the alert came in, Neubird immediately began its analysis, producing this detailed investigation.
Within minutes of implementing these recommendations, the success rate returned to normal levels. More importantly, Neubird's analysis helped prevent similar issues across other workflows by identifying potential bottlenecks before they impacted customers.
Moving from Reactive to Proactive
The true transformation comes from Neubird's ability to learn and improve over time. As it analyzes each incident, it builds a deeper understanding of your workflow patterns and their dependencies. This learning translates into proactive recommendations that help prevent future failures. For instance, after resolving the e-commerce platform's timeout issues, Neubird began monitoring similar patterns across all Step Functions workflows, identifying potential bottlenecks before they impacted production. Read more: Discover how SRE teams are evolving their Kubernetes monitoring with Prometheus and Grafana observability with AI. This shift from reactive troubleshooting to proactive optimization fundamentally changes how SRE teams operate. Instead of spending nights and weekends debugging complex workflow failures, teams can focus on architectural improvements and innovation. The continuous refinement of Neubird's analysis means that each incident makes your system more resilient, not just through immediate fixes but through deeper architectural insights.
Neubird AI Implementation Journey
Integrating Neubird into your Kubernetes environment is straightforward:
- Connect your existing observability tools - Neubird enhances rather than replaces your current monitoring stack. You can connect Neubird to CloudWatch, ServiceNow, Datadog, and other popular monitoring tools.
- Configure your preferred incident response workflows.
- Review Neubird's incident analysis, drill down with questions, and implement recommendations. Neubird provides detailed reports and visualizations that help you quickly grasp the situation and take appropriate action. You can also ask Neubird questions about the incident, such as "What were the contributing factors?" or "What are the recommended mitigation steps?".
The Future of Workflow Reliability
As cloud architectures become more complex, the old approach of adding more dashboards and alerts simply won't scale. Forward-thinking teams are embracing AI not just as a tool, but as an intelligent teammate that can understand, learn, and improve over time. Ready to transform how your team handles Step Functions failures? Contact us to see how Neubird can become your AI-powered SRE teammate and help your organization master complex workflow reliability. Book a demo or get in Touch.